10 Key Insights into Meta's Autodata: The AI Data Scientist Framework Revolutionizing Training Data
The race to build smarter artificial intelligence has long hit a wall—not just because of limited computing power, but because the quality of training data often falls short. Meta AI's RAM team has introduced a groundbreaking solution called Autodata, a framework that turns AI models into autonomous data scientists. Instead of relying on expensive human annotators at every step, Autodata creates, evaluates, and refines training datasets in a closed loop. Early tests on complex scientific reasoning show it dramatically outperforms older synthetic data methods. In this article, we'll break down the data quality bottleneck, how Autodata works, and why it could reshape the way we build AI.
1. The Data Quality Bottleneck
Building better AI models has always been about more than just raw compute power. The real challenge is data quality. Human-labeled data is expensive, time-consuming, and hard to scale. Traditional synthetic data generation methods try to fill the gap, but they often produce examples that are too easy or riddled with errors. Without a way to continuously check and improve quality during generation, researchers end up with datasets that don't push models to their full potential. This bottleneck has held back everything from language understanding to scientific problem-solving.
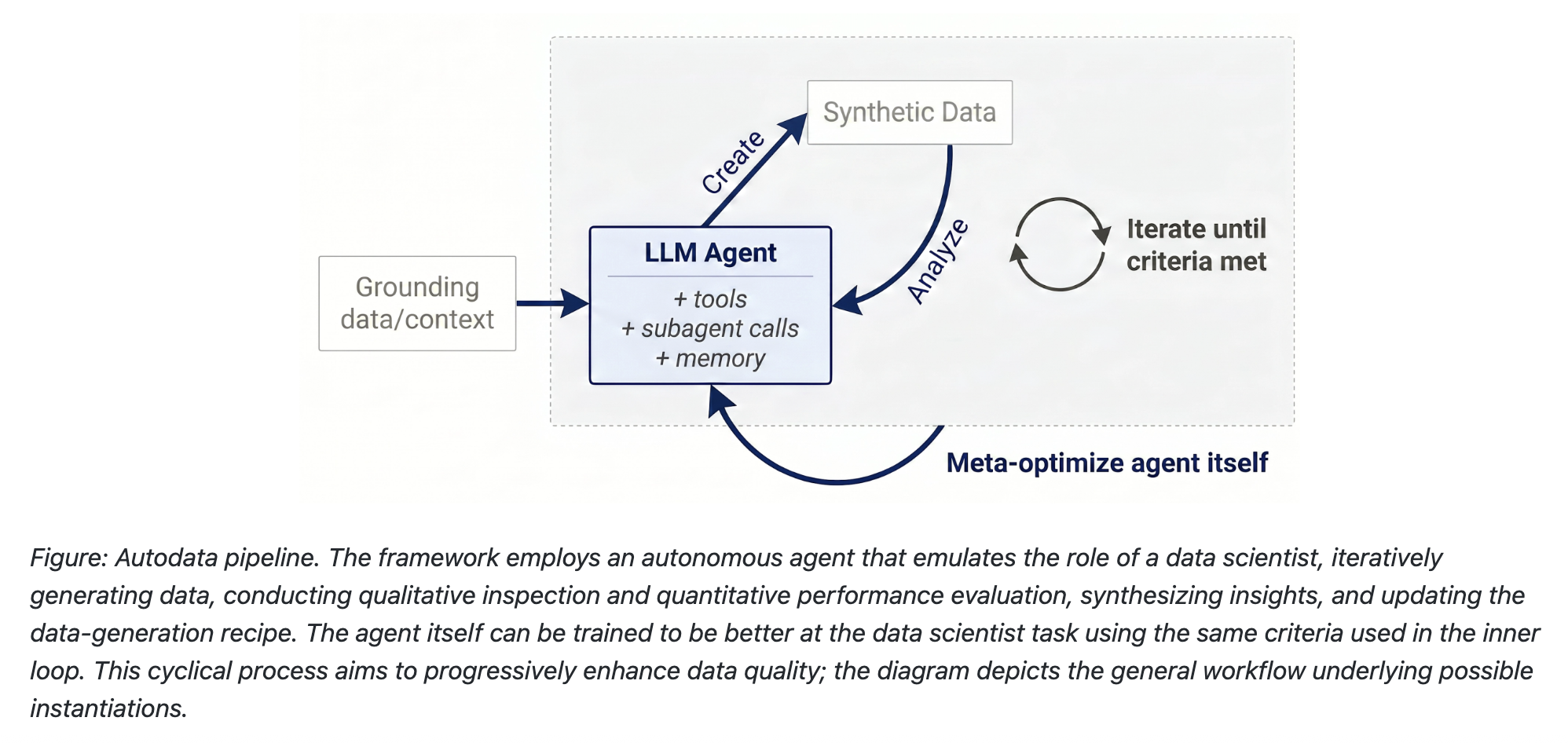
2. Enter Autodata: An Autonomous Data Scientist
Meta's RAM team designed Autodata to act like a real data scientist—only autonomous and tireless. Instead of generating training examples in a single pass, Autodata agents run a feedback-driven pipeline. They create data, analyze its correctness and difficulty, and then refine it based on what they learn. This mirrors how human experts iteratively improve datasets, but at machine speed. By removing the need for constant human oversight, Autodata can produce high-quality training data for complex tasks without the usual cost or delay.
3. How Synthetic Data Creation Has Evolved (and Where It Falls Short)
Previous approaches like Self-Instruct prompted large language models to generate new examples using zero-shot or few-shot prompts. Grounded Self-Instruct added document sources to reduce hallucinations. Chain-of-Thought Self-Instruct used reasoning steps to create more complex tasks. Most recently, Self-Challenging methods let a challenger agent interact with tools before proposing tasks. Yet all of these share a flaw: they generate data in a static, single-pass manner. There's no built-in feedback loop to catch mistakes or adjust difficulty on the fly. Autodata changes that by making generation iterative and self-correcting.
4. Autodata's Closed-Loop Pipeline
The heart of Autodata is a closed-loop pipeline that mimics a human data scientist's workflow. First, the agent creates training or evaluation examples by grounding itself on source documents—research papers, code, or legal texts. It uses tools and learned skills to generate high-quality content. Then, it analyzes what it created: checking for correctness, challenge level, and diversity. If the example fails any check, the agent revises it. This loop continues until the dataset meets predefined quality standards. The result is a dataset that is not only larger but also better than what traditional methods produce.
5. Data Creation: Grounded Generation with Tools
During the creation phase, Autodata agents don't just generate data out of thin air. They are grounded on source documents to ensure factual accuracy and reduce hallucination. For example, when building a scientific reasoning dataset, the agent might pull from research papers and then use external tools like calculators or code interpreters to generate complex problems. This grounded approach produces examples that are both diverse and realistic—far more useful than purely synthetic data that lacks context.
6. Data Analysis: Self-Evaluation and Quality Control
Once data is created, Autodata immediately shifts to analysis. The agent inspects each example for correctness: Is this answer logically sound? Is the problem challenging enough? Does it introduce rare or novel scenarios? It can even assign difficulty scores and flag potential biases. This self-evaluation step ensures that low-quality examples are caught and either fixed or discarded before they enter the training set. This kind of automated quality control is what sets Autodata apart from earlier methods.
7. Iterative Refinement: Learning from Mistakes
The most powerful feature of Autodata is its ability to iterate. If the analysis step reveals flaws—say, an example is too easy or contains an error—the agent goes back to the drawing board. It modifies the generation approach, adjusts the complexity, or incorporates feedback from previous rounds. This closed-loop pipeline means the dataset improves continuously, rather than being fixed after a single generation pass. Over time, the agent learns which strategies produce the best data, making the whole process smarter and more efficient.
8. Impressive Results on Scientific Reasoning
Meta tested Autodata on complex scientific reasoning problems—the kind that even top models struggle with. The results were striking: datasets created by Autodata significantly outperformed those from classical synthetic data methods like Self-Instruct or Self-Challenging. Models trained on Autodata-generated data showed higher accuracy on difficult physics, chemistry, and math questions. This proves that iterative, self-correcting data generation can produce training material that is not just abundant but genuinely high-quality.
9. Beyond Human Annotation: Cost and Speed
Human annotation remains the gold standard for data quality, but it's slow and expensive—especially for specialized domains like scientific research. Autodata offers a compelling alternative: it can generate and refine thousands of examples in the time it takes a human to produce a handful. While not every dataset will replace human input entirely, for many tasks Autodata's autonomous pipeline can match or exceed human-quality data at a fraction of the cost. This makes high-quality AI training accessible to more teams and projects.
10. What This Means for the Future of AI
Autodata points toward a future where AI models can generate their own training data with minimal human intervention. This could accelerate progress in fields like medicine, climate science, and robotics—where specialized data is scarce. By automating the tedious process of dataset creation and refinement, frameworks like Autodata free researchers to focus on harder problems. The shift from static synthetic data to dynamic, self-improving data generation is a paradigm change that could unlock the next wave of AI capabilities.
Meta's Autodata is more than just another synthetic data tool—it's a new way of thinking about how AI learns. By turning the model into an autonomous data scientist, we can finally break the data quality bottleneck. As the framework matures, expect to see it applied across industries, making AI training faster, cheaper, and more effective. The era of self-improving datasets has begun.